








Những năm trở lại đây người dùng mạng đã bắt đầu ý thức việc bảo vệ quyền riêng tư, từ chối chia sẻ dữ liệu cá nhân của mình. Điều này đã thôi thúc các hãng công nghệ khổng lồ như Google đã thông báo sẽ loại bỏ hoàn toàn cookie của bên thứ ba trước năm 2024; Apple tung ra khuôn khổ bảo mật ATT trên iOS 14.5, buộc các ứng dụng phải có được sự đồng ý của người dùng thì mới được phép theo dõi.
Việc cookie của bên thứ ba dần bị biến mất đi sẽ kéo theo sự tụt giảm của hiệu quả quảng cáo kỹ thuật số? khi không thể giúp các nhà quảng cáo theo dõi chính xác hành vi lướt web của người dùng, nhắm mục tiêu đến khách hàng tiềm năng để phân phối quảng cáo cá nhân hóa.
Tuy nhiên, trên thực tế còn có rất nhiều dữ liệu khác mà ta có thể tận dụng để duy trì hiệu quả quảng cáo. Sau đây, TenMax xin giới thiệu 6 loại dữ liệu mà nhà quảng cáo cần phải nắm rõ trước khi cookie của bên thứ ba biến mất hoàn toàn.
1. Dữ liệu của bên thứ nhất (First-party data)
Những thông tin mà doanh nghiệp thu thập trực tiếp từ người tiêu dùng và khách hàng tiềm năng thông qua các chiến dịch tiếp thị, website, bảng câu hỏi khảo sát… thì được xem là dữ liệu của bên thứ nhất, thuộc quyền quản lý của doanh nghiệp đó. Vì vậy, dữ liệu của bên thứ nhất được xem có độ tin cậy, chính xác và bảo mật cao.

Khi doanh nghiệp sở hữu một lượng lớn dữ liệu của bên thứ nhất, sử dụng đúng cách, đồng thời thiết lập các thông số nội bộ và tiêu chuẩn đo lường thì sẽ tạo nên cơ sở dữ liệu marketing của riêng mình. Điển hình là doanh thu quảng cáo trên các dịch vụ OTT (Over The Top) và CTV (Connected TV) đã tăng mạnh khi có số lượng người dùng đăng ký ngày một tăng.
Vận dụng dữ liệu của bên thứ nhất cần phải thông qua 3 giai đoạn sau:
- Thu thập dữ liệu (Data collection)
Hình thức đơn giản nhất đó là khi bạn ở quầy thanh toán, nhân viên sẽ hỏi bạn có muốn đăng ký làm thành viên hay không. Thế nhưng trong thế giới kỹ thuật số thì phức tạp hơn nhiều, bao gồm cả việc sử dụng công cụ ra sao để nắm bắt được hành vi lướt web/social media của người dùng… Ngoài ra, cách thức thu thập cũng sẽ ảnh hưởng đến hiệu quả quản lý và ứng dụng dữ liệu, do đó nhiều công ty quyết định đầu tư nền tảng quản lý dữ liệu (DMP) để phân loại dữ liệu ngay từ đầu vào, giúp việc phân tích ở giai đoạn tiếp theo được tiến hành nhanh hơn và hiệu quả hơn.
- Nhượng quyền dữ liệu (Data concession)
Nhận thức của người dùng về bảo vệ quyền riêng tư đang tăng lên; nếu họ không nhận được lợi ích nào thì đương nhiên sẽ không chia sẻ bất kỳ thông tin cá nhân nào. Do đó, doanh nghiệp cần phải có chiến lược giao tiếp rõ ràng, xây dựng content marketing có giá trị cao đối với người dùng, điều này sẽ giúp họ cảm thấy yên tâm, tin tưởng khi chia sẻ thông tin cá nhân cho doanh nghiệp.
- Quản lý dữ liệu (Data management)
Doanh nghiệp ngoài việc thu thập dữ liệu của bên thứ nhất nhằm tạo ra một cơ sở dữ liệu cho riêng mình, thì còn phải chú ý đến việc sử dụng và quản lý dữ liệu một cách hợp pháp nhằm tránh xảy ra các vấn đề như lạm dụng/rò rỉ dữ liệu. Nếu dữ liệu ấy không may bị kẻ xấu đánh cắp thì hình ảnh doanh nghiệp, niềm tin của khách hàng đối với doanh nghiệp sẽ khó gầy dựng lại.
Ưu & nhược điểm trong việc sử dụng dữ liệu của bên thứ nhất
Ưu điểm: có tính độc quyền, chính xác và hiệu quả cao; được doanh nghiệp thu thập dựa trên sự đồng ý của người dùng.
Nhược điểm: nếu doanh nghiệp không có chiến lược rõ ràng thì sẽ khó khăn để thu thập dữ liệu quy mô lớn. Ngoài ra, doanh nghiệp còn phải đảm bảo an toàn thông tin và bảo mật dữ liệu.
~.~.~.~.~.~.~.~.~.~
2. Dữ liệu của bên thứ hai (Second-party data)
Dữ liệu bên thứ hai được xem là phần mở rộng của dữ liệu bên thứ nhất. Nói một cách đơn giản là doanh nghiệp và đối tác của mình sẽ cùng nhau trao đổi và chia sẻ dữ liệu của bên thứ nhất (có tệp đối tượng tương tự nhưng lại được thu thập ở các mảng khác nhau), điều này giúp quy mô dữ liệu của hai bên sẽ tăng lên rất nhiều mà không cần phải vất vả thu thập chúng.
Ví dụ: các thương hiệu protein cao cấp có thể thu thập dữ liệu khách hàng từ các phòng tập gym; còn các thương hiệu đồng hồ cao cấp sẽ có thể thu thập nguồn dữ liệu khách hàng từ những trang web/blog du thu yền. Cả hai dòng sản phẩm đều cùng hướng đến đối tượng mục tiêu có sự trùng lắp cao, do đó phù hợp trong việc chia sẻ dữ liệu giữa hai bên.
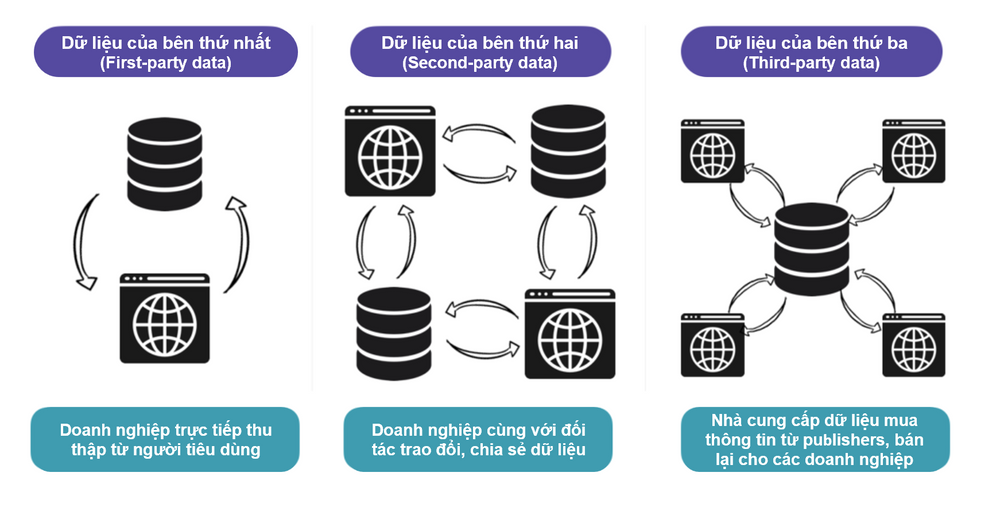
Ưu điểm: dữ liệu có thể mở rộng và đạt được quy mô lớn, giúp đạt được hiệu quả cao trong quảng cáo và đo lường.
Nhược điểm: người tiêu dùng không biết thông tin họ cung cấp sẽ được sử dụng và chia sẻ như thế nào; các chính sách bảo vệ riêng tư người dùng ngày càng được quy định nghiêm ngặt hơn. Vì thế, doanh nghiệp không những phải đảm bảo an toàn dữ liệu của người tiêu dùng, mà còn phải cho người tiêu dùng biết dữ liệu sẽ sử dụng trong những phạm vi nào.
~.~.~.~.~.~.~.~.~.~
3. Dữ liệu cấp độ gia đình (Household-level data)
Adam Broitman - Cố vấn cấp cao của công ty McKinsey & Company đã đưa ra nhận định rằng “dữ liệu thuộc cấp độ gia đình là nguồn lực chính của truyền thông và quảng cáo trong nhiều năm”, đặc biệt là đối với các doanh nghiệp chú trọng xây dựng/nâng cao giá trị nhận thức thương hiệu, vì thông qua loại dữ liệu này doanh nghiệp có thể tiếp cận được nhiều đối tượng nhất có thể.

Loại dữ liệu này ban đầu thường được sử dụng ở mảng quảng cáo truyền hình truyền thống; sau này do sự phát triển của nền tảng video/âm nhạc trực tuyến và sự phổ biến của smartphone/PC khiến số lượng người xem truyền hình truyền thống đã giảm đáng kể.
Tuy nhiên, do ảnh hưởng của dịch bệnh Covid-19 đã khiến người dùng dành nhiều thời gian ở nhà hơn và bắt đầu quay trở lại với màn hình TV để xem phim, ca nhạc... Một tỷ lệ lớn các hộ gia đình đã chuyển sang sử dụng các TV có tính năng kết nối Internet (CTV) để xem được các nội dung OTT (Over The Top). Trong bối cảnh như vậy, một số nhà sản xuất OTT/CTV đã tuyên bố rằng họ “có khả năng phân phối quảng cáo một cách chính xác đến các hộ gia đình”.
Ưu điểm: độ phủ sóng cao giúp tăng phạm vi tiếp cận của quảng cáo đến các đối tượng mục tiêu, tiếp tục phát huy những điểm nổi bật của quảng cáo truyền hình trước đây
Nhược điểm: không thể tiến hành phân khúc đối tượng một cách rõ ràng để phân phối các quảng cáo được cá nhân hóa
~.~.~.~.~.~.~.~.~.~
4. Dữ liệu ngữ cảnh (Contextual)
‘Nhắm mục tiêu theo ngữ cảnh’ từ lâu đã tồn tại trong lĩnh vực công nghệ quảng cáo, bằng việc quét nội dung trang web để xác định các từ khóa, từ đó phân phối quảng cáo có nội dung liên quan, và hầu như không cần phải dùng đến cookie để thu thập dữ liệu người dùng, không vi phạm đến quyền riêng tư.
Ví dụ: Người dùng khi lướt các trang web du lịch thì hành vi tung tích của họ sẽ bị cookie ghi lại, được gắn tag là đối tượng quan tâm đến du lịch, từ đây đối tượng ấy lúc nào cũng có khả năng thấy được quảng cáo du lịch dù là đang lướt web thể thao/tài chính. Tuy nhiên, đối với contextual targeting thì quảng cáo xuất hiện dựa vào nội dung, thể loại bài viết mà người dùng đang xem, như quảng cáo ưu đãi về thẻ tín dụng có thể xuất hiện trên các trang web tài chính, mà không phải trên quảng cáo làm đẹp.
Ưu điểm: bảo vệ quyền riêng tư của người dùng; quảng cáo xuất hiện phù hợp với nội dung bài viết của trang web, từ đó nâng cao mức độ trải nghiệm của người dùng.
Nhược điểm: mức độ nhắm đối tượng mục tiêu thấp, không thể phân phối quảng cáo cá nhân hóa.
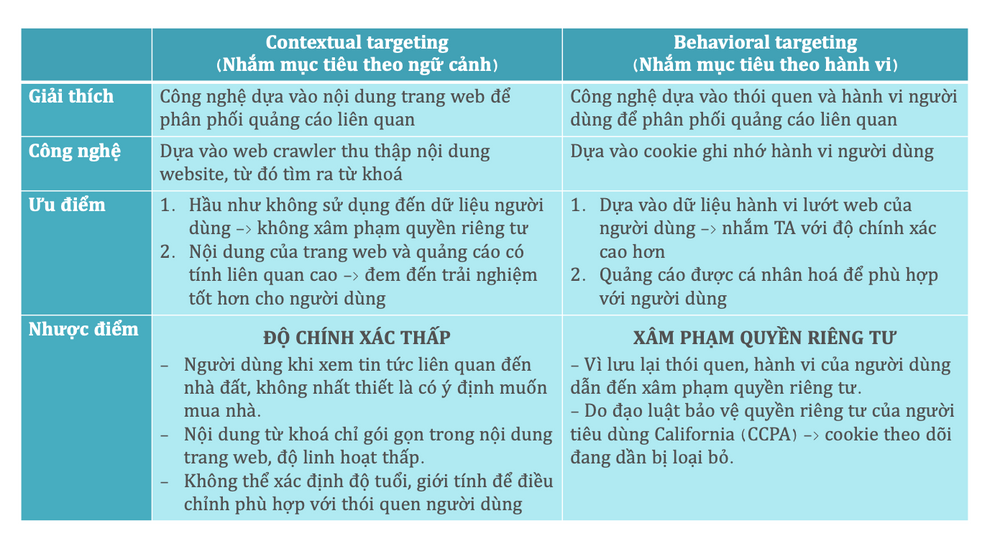
Contextual targeting vs Behavioral targeting
~.~.~.~.~.~.~.~.~.~
5. Biểu đồ nhận dạng (Identity graph)
Biểu đồ nhận dạng là cơ sở dữ liệu được sử dụng để theo dõi hành vi cá nhân của khách hàng trên tất cả các nền tảng đa thiết bị, từ đó tạo ra một mô hình thu nhỏ hoàn chỉnh, nắm bắt nhu cầu của khách hàng để phân phối quảng cáo một cách chính xác.
So với hệ thống CRM (Customer Relationship Management) thì biểu đồ nhận dạng không chỉ thu thập thông tin liên hệ và mã số thành viên, mà còn kết hợp dữ liệu khách hàng với mã nhận dạng cá nhân, như: e-mail, số điện thoại, ID thiết bị, hành vi lướt web, địa chỉ IP… kể cả cookie.
Cookie là công cụ thuận tiện và trực tiếp nhất để xây dựng biểu đồ nhận dạng, có thể thu thập nhiều loại dữ liệu hữu ích cùng một lúc. Tuy vậy, việc cookie biến mất không có nghĩa là biểu đồ nhận dạng cũng sẽ tan biến theo, nhưng nó cần phải được xây dựng dựa trên cấu trúc mang tính dài hạn. Ví dụ: cùng một thông tin đăng nhập trên các thiết bị di động thì có thể xây dựng lên biểu đồ nhận dạng qua thiết bị chéo.
Ưu & nhược điểm trong việc sử dụng biểu đồ nhận dạng
Ưu điểm: biểu đồ nhận dạng có thể tích hợp dữ liệu từ nhiều nguồn khác nhau, nhằm giúp doanh nghiệp thấu hiểu toàn diện về một khách hàng, sau đó cung cấp các dịch vụ và quảng cáo cá nhân hóa. Ngoài ra, nó còn giúp doanh nghiệp nắm bắt được hành vi của khách hàng trên nhiều thiết bị, giúp doanh nghiệp phân bổ ngân sách hiệu quả hơn đến các kênh tiếp thị.
Nhược điểm: xây dựng biểu đồ nhận dạng cần tốn rất nhiều công nghệ và nguồn lực, nhất là sau khi cookie bị xóa sổ đi. Vì thế, doanh nghiệp nên đánh giá, xem xét kỹ liệu mình có đủ khả năng tài chính để xây dựng biểu đồ nhận dạng và nó có thể mang lại lợi nhuận tương ứng hay không.
~.~.~.~.~.~.~.~.~.~
6. Dữ liệu tổ hợp (Cohort)
Công nghệ theo dõi FLoC (Federated Learning of Cohorts) là một phần quan trọng trong dự án Privacy Sandbox của Google, được dự đoán là có thể đạt tới hiệu quả 95% hiệu quả của 3rd-party cookie.
Thay vì cookie theo dõi lịch sử lướt web của từng cá nhân, thì FLoC chạy phân tích hành vi lướt web của bạn và đưa bạn vào một nhóm tổ hợp (cohort) gồm những người có sở thích tương tự (và không chia sẻ lịch sử duyệt web của bạn với Google). Nhóm tổ hợp ấy cung cấp vừa đủ điều kiện cho phép các Advertisers hiển thị các quảng cáo có liên quan, nhưng không quá chi tiết để Advertisers có thể nhận diện bạn.
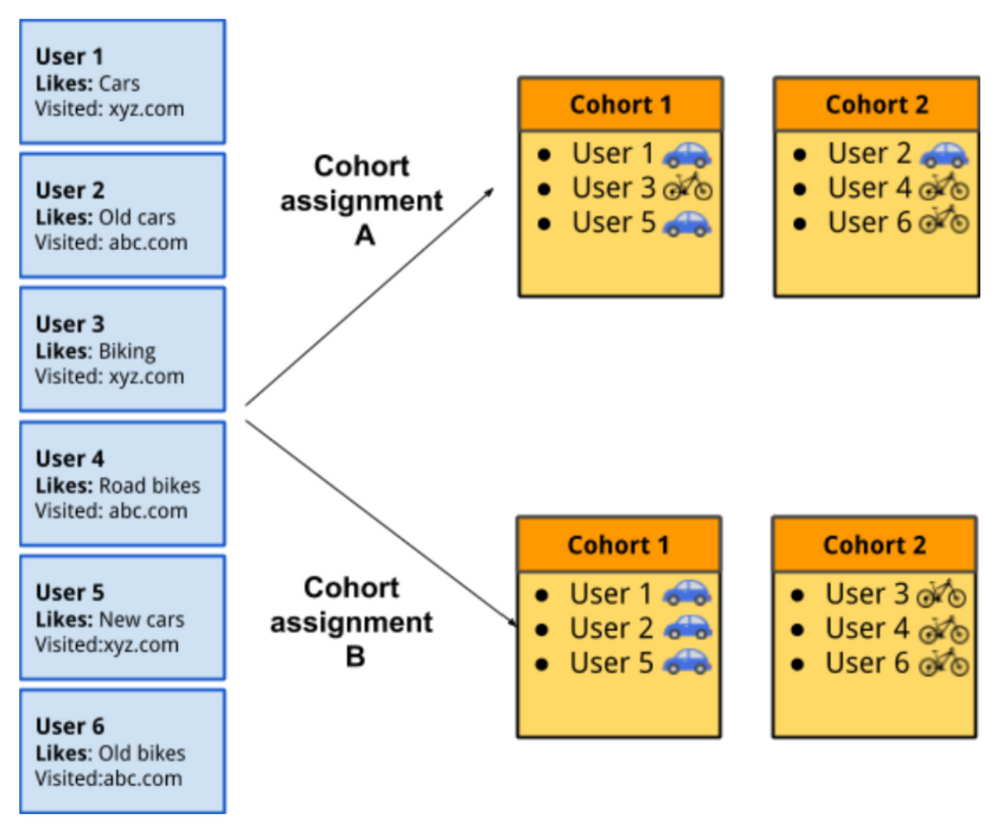
FLoC. Image credits: Google
Ưu điểm: về mặt lý thuyết thì FLoC có thể đảm bảo quyền riêng tư và hiệu quả phân phối quảng cáo.
Nhược điểm: nhiều nhà khoa học dữ liệu và kỹ sư phần mềm nghi ngờ việc phân chia thành nhóm có thể gia tăng sự phân biệt đối xử, dẫn đến xảy ra các cuộc tấn công mạng nhằm vào một nhóm cụ thể nào đó. Theo EFF (Electronic Frontier Foundation) cho rằng, mặc dù FLoC đã tránh nhắm mục tiêu trực tiếp vào người dùng dựa trên độ tuổi, giới tính, và thu nhập, nhưng vẫn có các công cụ hỗ trợ để phân biệt được những người dùng khác nhau. Đó cũng là nguyên nhân khiến FLoC không thể thử nghiệm ở EU; việc sử dụng dữ liệu cá nhân để tạo nhóm tổ hợp (cohort) mà không có sự đồng ý của người dùng thì có khả năng vi phạm vào “Quy định chung về bảo vệ dữ liệu (GDPR)” của EU.









