








Lựa chọn giữa domain model và meta model
Data Model là trái tim của mọi ứng dụng.
Cuối cùng, tất cả mọi thứ đều hướng về dữ liệu: Dữ liệu đến từ bàn phím người dùng hoặc từ nguồn bên ngoài, dữ liệu được xử lý theo một số quy tắc nghiệp vụ và cuối cùng dữ liệu được hiển thị cho người dùng (hoặc các ứng dụng bên ngoài) theo một cách tiện lợi nhất.
Mọi khía cạnh của ứng dụng, mọi chức năng bạn viết đều có dữ liệu liên quan để mang lại ý nghĩa cho toàn bộ hệ thống.
Vì vậy, câu hỏi đặt ra ở đây là: Các khía cạnh chính của một Data Modeling tốt là gì?
Câu trả lời sẽ được giải đáp cụ thể trong bài viết dưới đây, nhưng trước tiên hãy đến với 2 định nghĩa:
Định nghĩa 1: Data Model là gì?
Data Model là một cách để tổ chức dữ liệu của ứng dụng. Bản thân Data Model không phải là dữ liệu, cũng không phải là thiết bị bạn sử dụng để lưu trữ dữ liệu (hệ thống cơ sở dữ liệu bạn chọn). Do đó có thể khẳng định như sau:
- Bạn có thể lưu trữ cùng một dữ liệu sử dụng các mô hình dữ liệu khác nhau.
- Bạn có thể lưu trữ các dữ liệu khác nhau bằng cách sử dụng cùng một mô hình dữ liệu.
- Có thể chuyển đổi dữ liệu từ mô hình dữ liệu này sang mô hình dữ liệu khác (quá trình này thường được gọi là “Migration of Data - Chuyển giao dữ liệu”).
Định nghĩa 2: Làm thế nào chúng ta có thể định nghĩa một Data Model tốt?
Nói cách khác là làm thế nào chúng ta có thể so sánh các tùy chọn mô hình dữ liệu khác nhau? Hay những khía cạnh nào cần được xem xét?
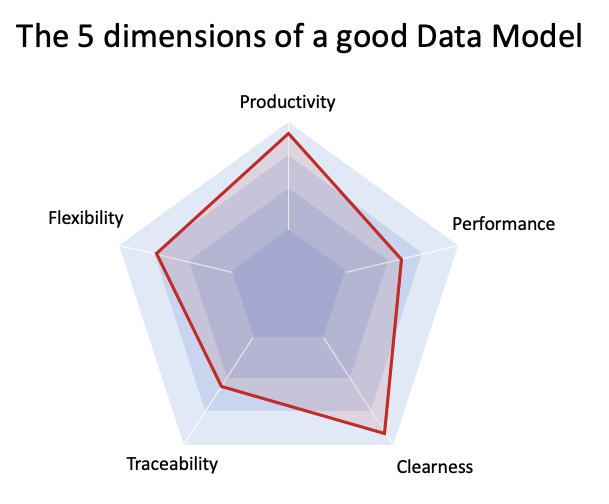
Có 5 khía cạnh liên quan đến một Data Model tốt:
- Tính rõ ràng: Sự dễ hiểu đối với những người sử dụng. Như bạn có thể đã biết, hầu hết thời gian developers đọc mã thay vì viết, vì vậy chúng ta cần hiểu rõ ràng những gì chúng ta đang làm với dữ liệu của mình.
- Tính linh hoạt: Khả năng phát triển của mô hình mà không cần phải tác động quá lớn đến các đoạn code. Công ty startup mà bạn làm việc đang phát triển, vì vậy các hệ thống sẽ thay đổi và các mô hình dữ liệu đằng sau chúng sẽ cần phải phát triển theo thời gian.
- Hiệu suất: Đây là một chủ đề rất rộng và bài viết này sẽ không nói về các nhà cung cấp cơ sở dữ liệu (database vendors)hoặc một số chỉnh sửa kỹ thuật để cải thiện tốc độ đọc và ghi dữ liệu. Cách thức thiết kế data model đúng đắn cũng đem lại lợi ích về hiệu suất. Chúng ta sẽ đi sâu hơn vào khía cạnh này ở phần sau.
- Năng suất: Dưới góc nhìn của lập trình viên (developer), chắc hẳn bạn sẽ muốn có một mô hình dữ liệu dễ làm việc mà không cần sử dụng nhiều thời gian (định nghĩa về năng suất).
- Khả năng truy xuất nguồn gốc: Cuối cùng, các công ty không chỉ muốn có dữ liệu liên quan đến người dùng của mình mà còn có dữ liệu liên quan đến chính hệ thống. Dữ liệu có thể cung cấp thông tin những gì đã xảy ra trong quá khứ, những giá trị công ty có tại một thời điểm nào đó.
Nói cách khác: để làm mọi người hài lòng, cần cung cấp Data Model dễ hiểu, dễ mở rộng hoặc thay đổi, có hiệu suất tốt đồng thời tốt cho năng suất của nhà phát triển và với khả năng hiểu biết những gì đã xảy ra trong quá khứ
Các kỹ thuật lập Data Modeling chính
Như bạn có thể đoán, bài viết này sẽ đề xuất một cách chung để lập mô hình dữ liệu đáp ứng tất cả các yêu cầu đặt ra. Thực tế sẽ không có bất kỳ cách thức hoàn hảo tuyệt đối nào và câu trả lời chính xác hầu hết thời gian là “” “còn tùy vào rất nhiều yếu tố”, nhưng tôi đã sử dụng kỹ thuật mới này và có vẻ rất hứa hẹn. Nhưng trước tiên, hãy tìm hiểu “cách thông thường” của việc lập mô hình dữ liệu mà chắc hẳn bạn sẽ cảm thấy rất quen thuộc.
Mô hình dữ liệu chuẩn (còn gọi là Domain Model)
Bạn xác định các đối tượng và thuộc tính của chúng dựa trên phạm vi của vấn đề bạn đang giải quyết. Giống như có một loại hộp khác nhau cho mỗi loại đồ vật mà chúng ta muốn cất giữ.
Giả sử bạn đang phát triển giải pháp phần mềm Meetings. Phạm vi của bạn sẽ trông giống như danh sách sau:
- Cuộc họp: Với thông tin cơ bản về địa điểm, thời gian, thời lượng và hoạt động như nơi các thực thể còn lại được liệt kê bên dưới hoạt động
- Con người: Các thành viên của cuộc họp có thể với một số vai trò cụ thể (người tổ chức, thư ký, người thuyết trình,...)
- Chủ đề: Chương trình cho cuộc họp dưới dạng danh sách các chủ đề với một số thứ tự, mô tả, thời lượng,...
- Thỏa thuận: Kết quả chính của cuộc trò chuyện có thể được gắn thẻ để thuận tiện tìm kiếm sau này.
- Ghi chú: Các cuộc trò chuyện chính bên trong một chủ đề.
- Hành động: Một số trách nhiệm ngắn hạn được giao cho một người.
Rõ ràng là loại mô hình này khá rõ ràng vì được định nghĩa giống như cách chúng ta nghĩ về vấn đề.
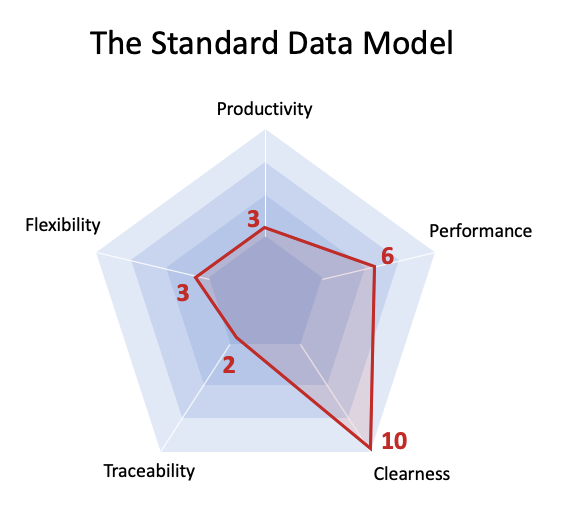
Vì vậy, đầu tiên hãy thực hiện kiểm tra về 5 khía cạnh phân tích (thang điểm từ 1 đến 10)
Sự thông suốt: 10 điểm. Có nghĩa là mô hình rất rõ ràng, giống như con người nghĩ.
Tính linh hoạt: 3 điểm. Yếu tố không thật sự tốt vì với mỗi lĩnh vực mới được yêu cầu, sẽ cần một sự thay đổi về mô hình.
Hiệu suất: 6 điểm. Loại mô hình này không có hiệu suất tốt nhất và lý do sẽ được trình bày sau đây.
Năng suất: 3 điểm. Mỗi bộ sưu tập (hoặc bảng) sẽ cần phương thức riêng để cập nhật giá trị trong mỗi trường. Điều này không tốt cho năng suất của lập trình viên, trừ khi bạn phát triển một phần mềm trung gian để giao tiếp với cơ sở dữ liệu theo “cách tham số” nhưng điều này cũng không tự nhiên. Chúng tôi sẽ đề xuất một cách tốt hơn để thực hiện điều này.
Khả năng truy xuất nguồn gốc: 2 điểm. Loại mô hình này cập nhật các trường dữ liệu ngay lập tức, vì vậy khi địa chỉ thay đổi, địa chỉ cũ sẽ bị mấtCách giải quyết là có một bảng riêng biệt ghi lại tất cả các thay đổi (bảng nhật ký) nhưng sẽ được tách biệt với phần còn lại của mô hình.
Một cách tiếp cận mô hình hóa tổng hợp
Cấu trúc của mô hình
Đề xuất chỉ có một bảng (hoặc bộ sưu tập) lưu trữ tất cả dữ liệu miền, theo cùng một cấu trúc và không làm mất bất kỳ dữ liệu nào (không cập nhật, không xóa). Có 2 ngoại lệ đối với quy tắc này, chúng tôi sẽ đề cập đến chúng ở phần sau.

Cấu trúc của “universal record” này là:
- _id: Định danh duy nhất của thực thể.
- uniqueKey: (Tùy chọn) Đây cũng là một mã định danh duy nhất của thực thể nhưng được điều khiển bởi một số quy tắc kinh doanh. Ví dụ: địa chỉ email phải là duy nhất hoặc mối quan hệ giữa hai thực thể có thể tạo ra một thực thể mới có khóa duy nhất là “entity_id_1 - entity_id_2”.
- domain: Loại thông tin đang lưu trữ. Hầu hết tất cả đều hữu ích cho việc lọc tìm nạp dữ liệu và có tính rõ ràng cho nhà phát triển khi xem cơ sở dữ liệu.
- company_id: Trường này có thể gây tranh cãi, nhưng trong một số ứng dụng đã phát triển về khái niệm công ty (tổ chức mà người dùng của bạn thuộc về) luôn hiện hữu giúp tăng tính rõ ràng của mô hình dữ liệu khi có 1 trường dữ liệu chứa tất cả các domain liên quan
- Mối quan hệ của dữ liệu: Bây giờ chúng ta đang suy nghĩ về các mối quan hệ. Hãy cho rằng có một bảng, không có quan hệ rõ ràng nào ở cấp mô hình (hoặc có ở cấp dữ liệu). Ở đây, bạn có thể xác định thực thể gốc của thực thể hiện tại, vì vậy khi có quyền truy cập vào thực thể gốc, bạn cũng sẽ có quyền truy cập vào thực thể này. Đây có thể là company_id hoặc user_id cho hầu hết các trường hợp.
- attrs: Đây là nơi chứa Dữ liệu thực tế, là một mảng các đối tượng ở dạng {key, value, timestamp}.

Trường attrs
Với trường này, toàn bộ mô hình thực sự nằm trong trường attrs và mỗi khóa có thể nhiều hơn một lần (đối với các mốc thời gian “timestamp” khác nhau).
Ví dụ:
- {key: ‘name’, value: ‘José’,timestamp: 1575490495682}.
- {key: ‘name’, value: ‘José Manuel’,timestamp: 1575490495795}.
Cho biết rằng cùng một tên khóa có giá trị 'José' tại timestamp 1575490495682, nhưng sau đó đã đổi thành 'José Manuel' tại 1575490495795. Do dấu thời gian này lớn hơn dấu thời gian trước đó, chúng tôi xem giá trị này là giá trị hiện tại.
Ngoài ra, sẽ luôn có 3 trường đặc biệt bên trong trường attrs:
- company_id: Đã được giải thích.
- user_id: Hoặc người dùng chịu trách nhiệm về việc tạo thực thể.
- trạng thái: Giá trị 1 cho các thực thể đang hoạt động và -1 cho những gì đã xóa (mặc dù thực sự không bao giờ xóa một thực thể)
Lưu ý rằng “hình dạng” của thuộc tính giá trị bên trong mỗi thuộc tính có thể thuộc bất kỳ kiểu nào. Nếu chúng ta nghĩ theo thuật ngữ Javascript, chúng ta có thể có: Chuỗi, Booleans, Số, Ngày, Mảng, Đối tượng,...

Bây giờ, đã đến lúc xem chi tiết từng khía cạnh trong phân tích 5 khía cạnh của Data Modeling.
Sự thông suốt
Đây không phải là tính năng lớn nhất của mô hình này, bởi vì mỗi khi bạn nhìn vào một bản ghi, bạn cần phải đi sâu vào bên trong trường attrs. Đây là chi phí chúng tôi phải trả, sự đánh đổi để có được những lợi ích khác.
Mặc dù sau khi làm việc với mô hình giá trị quan trọng này một thời gian, bạn sẽ “thấy mô hình rất rõ ràng”, nhưng đối với người đọc, thoạt nghe có vẻ khó hiểu.
Bạn sẽ nhận một phần thưởng tuyệt vời khi lập mô hình như thế này bằng cách mô tả tất cả mô hình của mình bằng một câu truy vấn. Vì vậy, nếu chúng ta cần có một tài liệu (hoặc tốt hơn là một trang web) hiển thị các trường "thực" của mỗi thực thể, chúng ta có thể đạt được điều đó rất dễ dàng.
Bây giờ, hãy xem xét sự linh hoạt của mô hình.
Linh hoạt
Tính linh hoạt được tích hợp trong mô hình meta và đó là khái niệm cốt lõi. Thay vì xác định trước các trường của thực thể cho mỗi phạm vi (còn được gọi là “lược đồ”), chúng tôi chỉ xác định cấu trúc chung này có thể chứa bất kỳ lược đồ nào.
Tính linh hoạt thực sự mạnh mẽ trong trường hợp này:
- Hệ thống của bạn cần lưu trữ loại dữ liệu mới tại một thực thể nhất định hoặc có thể là các thực thể mới. Bạn đã biết rằng bất kỳ thực thể nào cũng có thể được mô hình hóa bằng định nghĩa khóa giá trị (Key-value) đơn giản, vì vậy bạn sẽ không phá vỡ bất kỳ đoạn mã nào bằng cách thực hiện thay đổi này. Vấn đề là mô hình thực sự nằm bên trong dữ liệu, không phải bên trong cơ sở dữ liệu.
- Bạn cần thay đổi mối quan hệ giữa các thực thể, có thể có một thực thể phụ thuộc vào người dùng, và bây giờ cần phụ thuộc vào một nhóm người dùng…Đừng lo lắng, bạn chỉ cần cập nhật trường mối quan hệ bằng một truy vấn. Trong trường hợp này, có thể bạn sẽ cần thay đổi mã, nhưng bạn (một lần nữa) không cần phải thay đổi mô hình.
Hiệu suất
Hiệu suất là một lợi ích ít rõ ràng nhất của loại mô hình này. Bạn có thể lập luận rằng mô hình này chiếm nhiều không gian hơn mô hình truyền thống. Nhưng ngày nay việc lưu trữ không phải là một vấn đề vì có nhiều cách thức thực hiện khác nhau với chi phí thấp.
Hiệu suất chính không liên quan đến cách lưu trữ khóa giá trị, nhưng với trường dấu thời gian kết hợp với trường mà chúng tôi không bao giờ cập nhật hoặc xóa bất kỳ thứ gì.
Do đó, khi khách hàng đọc từ mô hình này (nơi có thể cảm nhận được hiệu suất mô hình) không cần phải lấy tất cả các thực thể, cũng như tất cả các trường thực thể mà họ quan tâm, bởi vì họ có thể đã có sẵn thông tin.
Ví dụ:
- Một số dữ liệu đã được tạo trong cơ sở dữ liệu tại dấu thời gian t_0.
- Một khách hàng xem ứng dụng yêu cầu một số dữ liệu tại t_1 và máy chủ trả lời bằng dữ liệu mà khách hàng quan tâm (chỉ dữ liệu mà module yêu cầu/có quyền truy cập). Sau đó, khách hàng đăng xuất ứng dụng tại dấu thời gian t_1.
- Tiếp đến, tại dấu thời gian t_2 và t_3, máy chủ nhận dữ liệu mới, cung cấp thông tin đến cho những người dùng khác đã tương tác với ứng dụng.
- Và sau đó, tại t_4, khách hàng kết nối lại và thay vì xem lại tất cả thông tin (cộng thêm thông tin mới), khách hàng chỉ nhận thông tin mới cần thiết, tránh lãng phí khi chuyển lại dữ liệu khách hàng đã có .
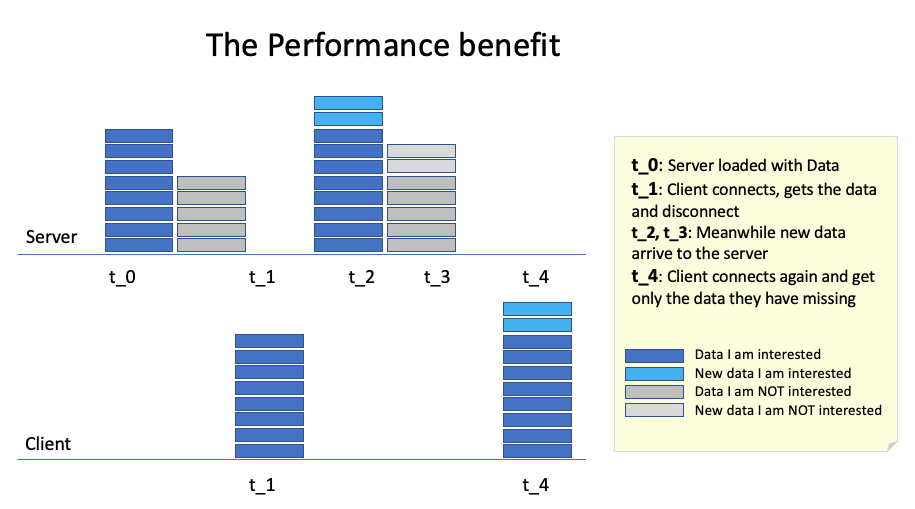
Quá trình này khá tốt cho hiệu suất. Thay vì điều chỉnh một số chi tiết nhỏ, chúng tôi lược bỏ rất nhiều công việc mỗi khi truy cập cơ sở dữ liệu bằng cách truy vấn: Chỉ cần cung cấp cho tôi những dữ liệu từ mốc thời gian này về trước.
Điều này không chỉ hoạt động ở cấp thực thể (các thực thể mới sẽ được gửi) mà còn ở cấp trường (chỉ gửi trường mới của các thực thể cũ), giảm dung lượng cần trao đổi về lâu dài.
Nói cách khác, chúng tôi đang triển khai một bộ nhớ cache cục bộ, điều đó có thể xảy ra chỉ vì chúng tôi không cập nhật các trường, mà chỉ hướng đến việc bổ sung dữ liệu mới.
Trong trường hợp nào chúng ta phá vỡ quy tắc "Chỉ thêm vào - không xóa hay cập nhật dữ liệu"?
Có 2 tình huống cần xem xét, đề phòng trường hợp bạn băn khoăn không biết làm thế nào để quản lý:
1. Trường chỉ là trạng thái, có tính biến động. Giả sử bạn đã gửi thông báo cho người dùng của mình. Người dùng có thể muốn đánh dấu là đã đọc hoặc chưa đọc và có thể thực hiện quá trình này nhiều lần. Vì vậy, không có giá trị thực nào giữ tất cả "lịch sử nhấp chuột", vì bản chất của dữ liệu.
2. Trường đại diện cho một thực thể con, ví dụ: bạn có thể có một domian gọi là "Kỹ năng" có "điểm" từ 1 đến n. Bạn có thể tạo một domain mới có tên “SkillGrades” nhưng là một thực thể con sẽ đơn giản hơn nếu được lồng vào bên trong domian gốc. Vấn đề là thay vì có nhiều khóa = 'điểm' cho mỗi lần bạn thêm hoặc xóa điểm, bạn chỉ có một khóa = 'điểm' và bạn thêm vào bên trong.
Trong cả hai trường hợp, chúng tôi cập nhật timestamp của các trường này trong mỗi lần cập nhật. Vì vậy, timestamp sẽ được công nhận là thông tin mới vào lần tiếp theo khách hàng yêu cầu.
Năng suất
Nếu bạn có 20–30 loại thực thể trong mô hình của mình (và không quá khó để đạt được con số này), bạn sẽ cần phải có một số phương thức CRUD (Tạo-Đọc-Cập nhật-Xóa) cho từng thực thể. Vì vậy, bạn sẽ có khoảng 100 phương pháp được sử dụng trong từng trường hợp.
Sao chép mã hiện có từ một phương thức, thay đổi tên tệp,, thay đổi nội dung của phương thức, thêm/xóa trường,...Mỗi khi bạn thay đổi các trường của thực thể thì sẽ xảy ra điều gì? Định vị tệp, thay đổi trường, khởi động lại máy chủ…
Khi bạn có một mô hình meta, bạn sẽ nhanh chóng nhận ra rằng bạn cần phải xây dựng một số chức năng tiện ích để tương tác. Tuy nhiên sự khác biệt với 100 phương thức được đề cập ở trên là tập hợp các tiện ích nhỏ hơn và không phụ thuộc vào quy mô domain của bạn Dưới đây là một số chức năng nên xem xét:
- createEntity: Tạo cấu trúc cơ bản và đó là thực thể không tính đến đúng sai (giống như tất cả các chức năng khác bên dưới).
- addAttrsToEntity: Chức năng “cập nhật”, cho phép thêm dữ liệu mới vào thực thể mà không làm mất dữ liệu trước đó.
- addParentKey: Thêm “thông tin quan hệ” của thực thể, để có thể xác định sau này ai có thể truy cập vào các dữ liệu này.
- getEntities: Bằng _id hoặc uniqueKey, bạn nhận được dữ liệu thực thể.
- pickKeyCurrentValue: Hầu hết thời gian chúng ta chỉ quan tâm đến giá trị cuối cùng (hiện tại) của mỗi trường, vì vậy chúng ta chuyển một thực thể cho phương thức này và một số khóa để trả về và chúng ta nhận được một đối tượng có giá trị cuối cùng cho mỗi khóa.
- getRelatedEntities: Cho phép trả về các thực thể ở cấp công ty (tất cả người dùng đều có quyền truy cập) ở cấp người dùng hoặc các cấp khác (ví dụ: route, tham số truy vấn).
Bạn sẽ mong đợi có ít hơn khoảng 50% đến 70% khối lượng mã cần được viết, nhưng cũng ít lỗi hơn do đã được tiêu chuẩn hóa.
Truy xuất nguồn gốc
Nếu bạn xóa dữ liệu (vật lý) hoặc cập nhật dữ liệu tại chỗ (cách tiếp cận phổ biến nhất), bạn đang mất khả năng biết những gì đã xảy ra trong quá khứ. Đôi khi đây là những gì bạn thực sự mong muốn (ví dụ trong 2 trường hợp đã nêu ở trên) nhưng những lúc khác bạn chỉ cảm thấy an toàn hơn.
Bạn biết rằng cơ sở dữ liệu không chỉ lưu giữ dữ liệu có liên quan đến người dùng của bạn mà còn lưu giữ các sự kiện liên quan đến từng phần dữ liệu. Điều này tốt cho các công việc sau này như:
- Gỡ lỗi (debug): Bạn có thể "thực sự thấy những gì đã xảy ra"
- Phân tích: Bạn cũng có khái niệm về tình trạng hoạt động của ứng dụng bạn đang xây dựng bằng cách xem cơ sở dữ liệu.
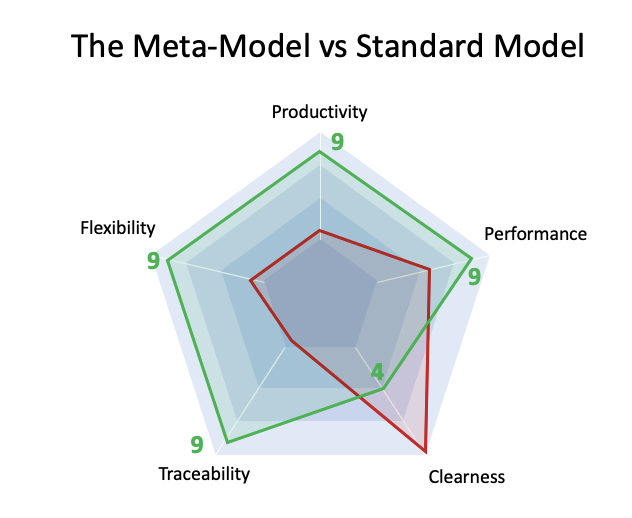
Tiếp theo, chúng ta hãy xem xét các con số với cách tiếp cận mới:
Meta-Model có những lợi thế rõ ràng trong mỗi chiều, ngoại trừ việc ít rõ ràng hơn (mặc dù bạn có thể điều chỉnh ý định của mình theo mô hình này theo thời gian). Lấy hình ảnh chỉ để so sánh 2 phương án, các con số là tùy ý và không dựa trên các nghiên cứu nghiêm túc.
Vậy điều gì liên quan đến việc sử dụng mô hình này trong Browser?
Đây có thể là “phần 2” của bài viết này, nhưng tóm lại, các khía cạnh chính là:
- Có một bản sao cục bộ của dữ liệu nhận được từ máy chủ tại LocalStorage (hoặc thậm chí tốt hơn trong IndexedDB). Dữ liệu này chỉ được tận dụng khi có dữ liệu mới.
- Sau đó, chúng tôi sẽ điền vào một đối tượng (một đối tượng JS lớn) với tất cả dữ liệu với 2 phép biến đổi:
1) Chúng tôi sẽ chỉ có giá trị cuối cùng của mỗi trường (dấu thời gian sẽ không còn cần thiết)
2) Thay vì có dữ liệu ở dạng [{key: 'name', value: 'José}, {key:' city ', value:' Santiago '}], chúng ta sẽ có dữ liệu giống như {name:' José ', thành phố:' Santiago '}. Vì vậy, dữ liệu sẽ tự nhiên hơn đối với mô hình tư duy.
Điều này rất quan trọng, bởi vì bất kỳ ai cũng đều đang quan tâm đến “khả năng truy cập” vào đoạn mã mà khách hàng cũng có. Khi dữ liệu mới được tạo ra bởi người dùng, bạn sẽ thêm dữ liệu vào đối tượng JS lớn của mình và cũng thực hiện yêu cầu đến máy chủ, vì vậy giao diện người dùng sẽ phản ánh các thay đổi ngay lập tức.
Cuối cùng nhưng không kém phần quan trọng, việc xây dựng Module quản trị qua Mô hình Meta (tạo, xóa, cập nhật dữ liệu mới) cũng rất dễ thực hiện. Bạn sẽ dùng ít đoạn mã đặc biệt hơn cho mỗi bộ sưu tập, các đoạn mã bạn viết sẽ có tính nhất quán hơn và chỉ cần ít thành phần UI để viết code.
Nguồn: itnext

![[SocialTrend Ranking] Bảng xếp hạng chủ đề đang HOT trên Mạng xã hội tuần 09/04 - 15/04/2024](https://media-api.advertisingvietnam.com/oapi/v1/media?uuid=e2cd8169-f95f-4b03-b4b5-be5a275cf16a&resolution=362x191&type=image)











