Ngày 22/10, Reddit chính thức đâm đơn kiện Perplexity AI cùng ba công ty thu thập dữ liệu khác, cáo buộc họ “ăn cắp” nội dung do người dùng tạo ra mà không xin phép để cung cấp cho hệ thống trí tuệ nhân tạo. Đây là một bước ngoặt quan trọng trong cuộc chiến giữa các nền tảng nội dung và công ty phát triển AI, nơi quyền sử dụng dữ liệu và bảo vệ quyền người dùng trở thành tâm điểm.
Tổng quan bối cảnh: Dữ liệu - món vàng của làng AI
Trong thế giới AI, dữ liệu được ví như là gia vị chính để đưa ra được món ăn ngon. Muốn chatbot thông minh, muốn công cụ trả lời tự động mượt mà… tất cả đều phải được “nuôi” bằng lượng dữ liệu khổng lồ, càng thật, càng đa dạng càng tốt. Và không ở đâu có dữ liệu người thật, việc thật phong phú bằng Reddit.
Reddit là nơi mọi người bàn từ chuyện tình yêu, học hành, công nghệ cho đến chính trị. Với hàng trăm nghìn cộng đồng (subreddit) và hàng chục triệu người dùng hoạt động mỗi ngày, đây là kho kiến thức, cảm xúc và tranh luận mà các công ty AI khao khát. Reddit biết rõ giá trị của mình, nên họ bắt đầu bán quyền truy cập dữ liệu cho các ông lớn như Google hay OpenAI như vậy thì vừa tạo doanh thu, vừa đảm bảo dữ liệu được dùng hợp pháp.
Ảnh: 54 trang tài liệu mà Reddit tố cáo Perplexity và ba nhà cung cấp dịch vụ thu thập dữ liệu khác (Nguồn: The Verge)
Nhưng rồi một startup non trẻ như Perplexity AI lại ngang nhiên dùng free mà không trả phí. Reddit cho rằng Perplexity đã vượt rào, không chịu trả phí bản quyền dữ liệu mà chọn cách lách luật đi vòng khi thu thập (scrape) dữ liệu từ kết quả tìm kiếm Google thay vì từ trang Reddit trực tiếp. Đáng chú ý, theo PPC, chỉ trong hai tuần tháng 07/2025, các công ty bị đơn đã quét gần 3 tỷ trang kết quả Google chứa nội dung Reddit. Nói cách khác, họ đã hút dữ liệu gián tiếp qua Google để né tường bảo vệ của Reddit.
Quan điểm của Reddit: “Đây không khác gì cướp ngân hàng”
Reddit cũng không hề nhẹ lời khi miêu tả hành động của các bị đơn như những tên cướp ngân hàng: “Biết rằng không thể vào kho tiền của ngân hàng, họ phá vào xe bảo an chở tiền”. Theo Reddit, Perplexity “rất cần” dữ liệu này cho hệ thống AI của mình, nhưng thay vì thương lượng cấp phép hợp pháp thì họ lại chọn đường “thu thập dữ liệu bất hợp pháp”.
Ben Lee, Giám đốc pháp lý của Reddit gọi đây là “nền kinh tế rửa dữ liệu quy mô công nghiệp” (industrial-scale data laundering), các công ty AI tìm mọi cách “tẩy trắng” dữ liệu thu thập được, biến nội dung của người dùng thành hàng hóa mà không xin phép. Ngoài ra còn nhấn mạnh rằng khi các công ty AI đua nhau lấy dữ liệu người dùng thật, thì tất nhiên nền tảng như Reddit sẽ biến thành mục tiêu.

Trước đó, theo The Verge đưa tin, Reddit thậm chí còn bẫy Perplexity bằng cách tạo một bài đăng ảo chỉ cấp phép cho mình Google nhìn thấy và chỉ vài giờ sau, nội dung đó lại xuất hiện trong câu trả lời của Perplexity. Với Reddit, đó là “bằng chứng không thể chối cãi”. Hồ sơ kiện nêu rõ Reddit yêu cầu phán quyết chặn bị đơn tiếp tục truy cập hoặc sử dụng dữ liệu Reddit, xóa hoặc ngừng sử dụng bất kỳ dữ liệu nào đã thu thập trái phép, và bồi thường thiệt hại bao gồm cả phần lợi nhuận mà các bị đơn kiếm được từ dữ liệu này.
Phản hồi của Perplexity: “Chúng tôi không ăn cắp, chỉ tóm tắt công khai”
Phía Perplexity AI nhanh chóng đáp trả rằng họ “không dùng dữ liệu Reddit để đào tạo mô hình AI” mà chỉ tóm tắt các cuộc thảo luận công khai, giống như cách người dùng chia sẻ link với nhau. Perplexity cho rằng vụ kiện là chiêu “chơi lớn” của Reddit để gây áp lực với các đối tác lớn hơn như Google hay OpenAI trong các thương vụ dữ liệu, chứ không phải vì Perplexity.
Perplexity còn trực tiếp đăng thông cáo ngay trên chính tài khoản Reddit của Perplexity AI như một cách “đáp trả trên sân nhà” của Reddit và khẳng định đã tuân thủ đúng robot.txt của Reddit và nhấn mạnh sẽ “không cúi đầu trước những hành động cưỡng ép” và sẽ chiến đấu vì “một internet mở cho tất cả mọi người”.
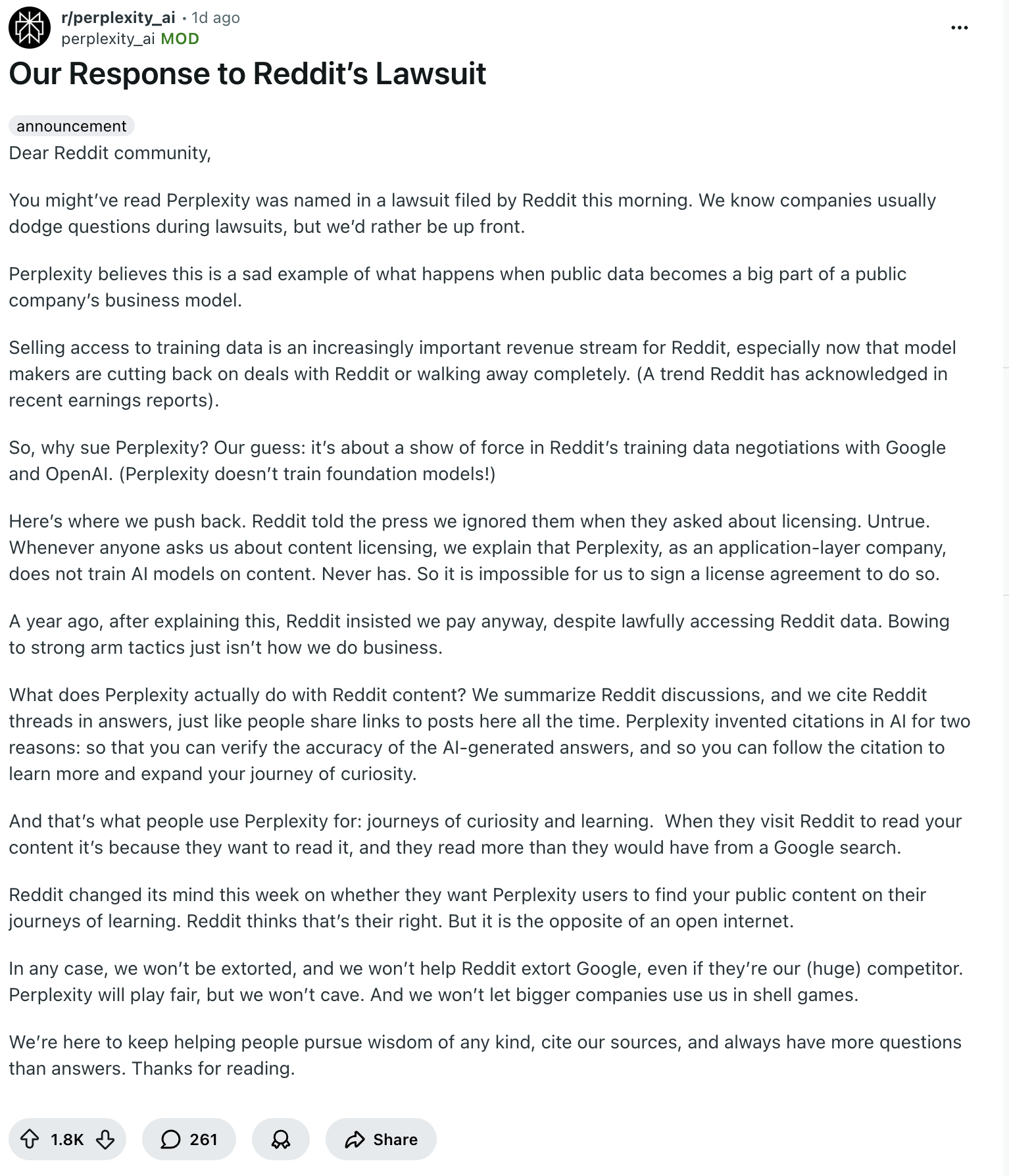
Ảnh: Lời hồi đáp của Perplexity về cáo buộc trên Reddit
Dù vậy, Reddit lại phát hiện rằng sau khi gửi thư cảnh báo hồi tháng 5, lượng kết quả có trích Reddit trong câu trả lời của Perplexity tăng gấp 40 lần khiến dư luận càng nghi ngờ rằng câu chuyện “chỉ tóm tắt công khai” không đơn giản như lời họ nói.
Vụ kiện được xem như một tiền lệ quan trọng: Nó không chỉ ảnh hưởng đến mối quan hệ giữa các nền tảng nội dung và các công ty AI, mà còn đặt ra câu hỏi về quyền dữ liệu người dùng, giấy phép dữ liệu trong kỷ nguyên AI, và giới hạn cho việc sử dụng dữ liệu công khai để đào tạo AI. Cho tới khi có phán quyết, ngành công nghệ và truyền thông đang theo dõi sát sao vì kết quả có thể định hình cách các công ty AI thu thập, xử lý và sử dụng dữ liệu trong tương lai.
Bảo Trân
Subscribe Newsletter của Advertising Vietnam để theo dõi nhiều tin tức hấp dẫn về ngành quảng cáo